GEOSPATIAL RISK AND PROTECTIVE FACTOR ANALYSIS:
An Overview of the Data Analysis Process During the PAP Program
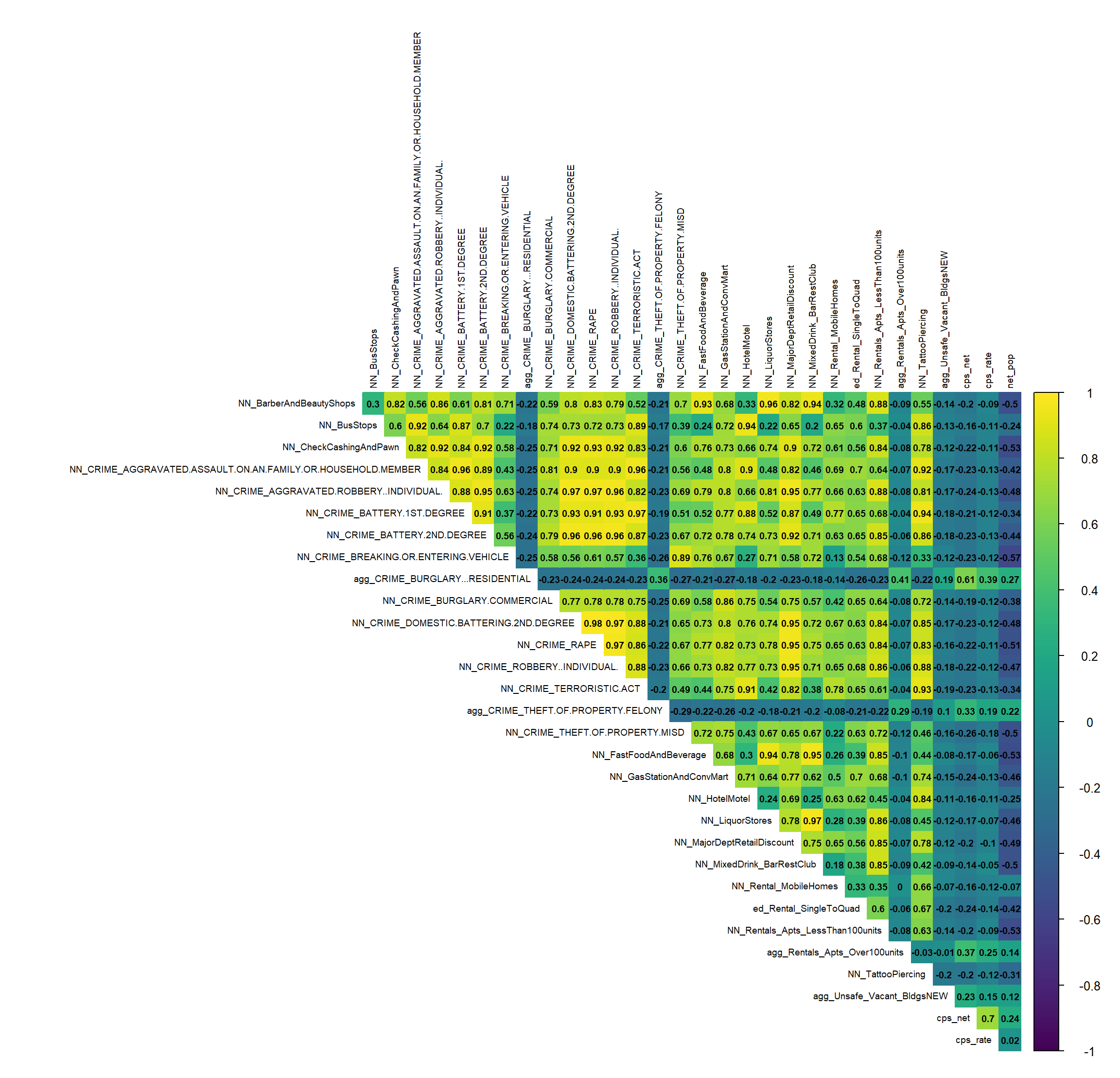
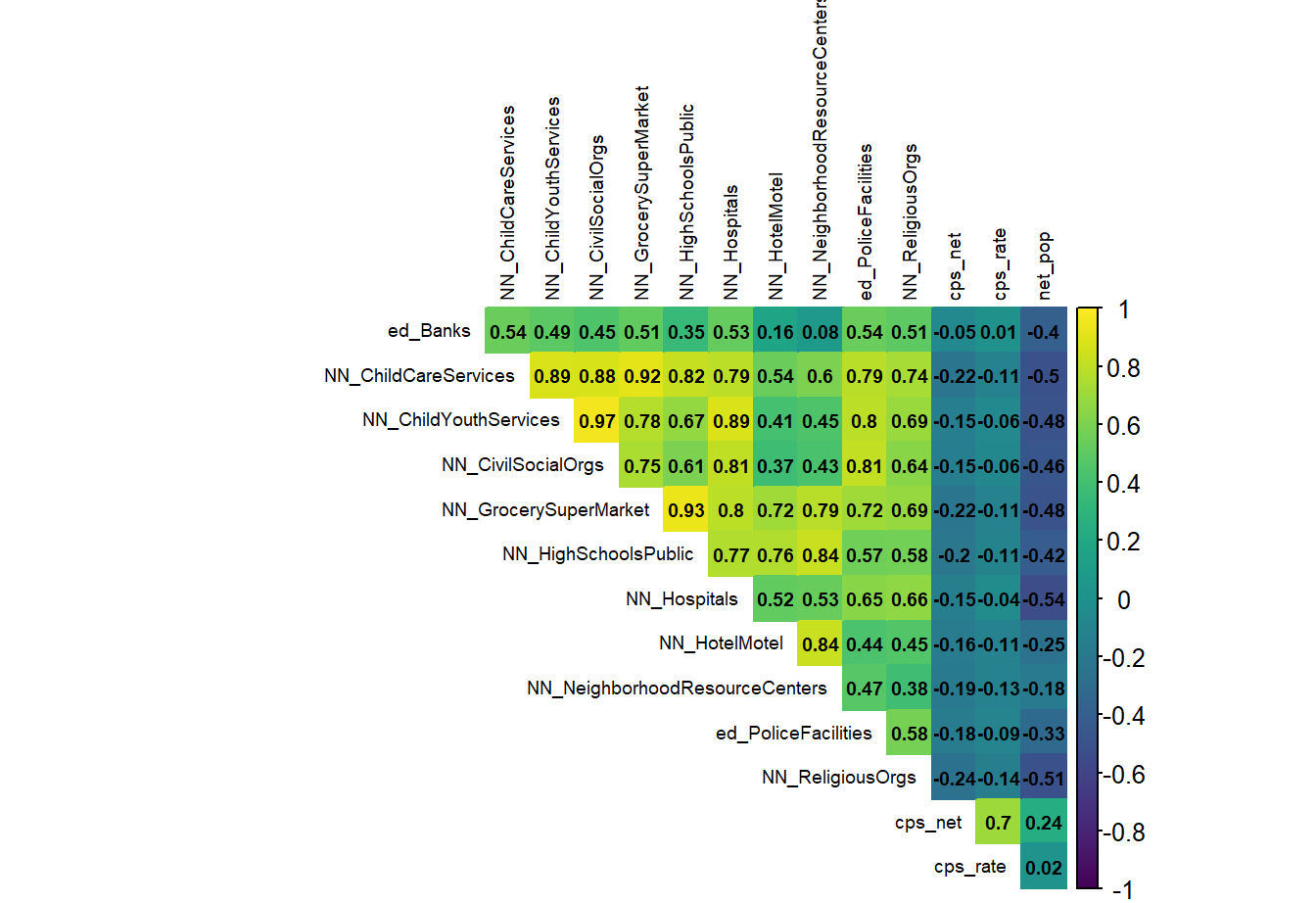
The intuition behind the modeling process is to borrow the observed maltreatment ‘experience’ and test whether those experiences are generalizable to places where maltreatment may occur but are not directly observed. This is done by using data associated with ‘neighborhood effects’ (individual, family, and household-level factors) that may be influencing maltreatment.
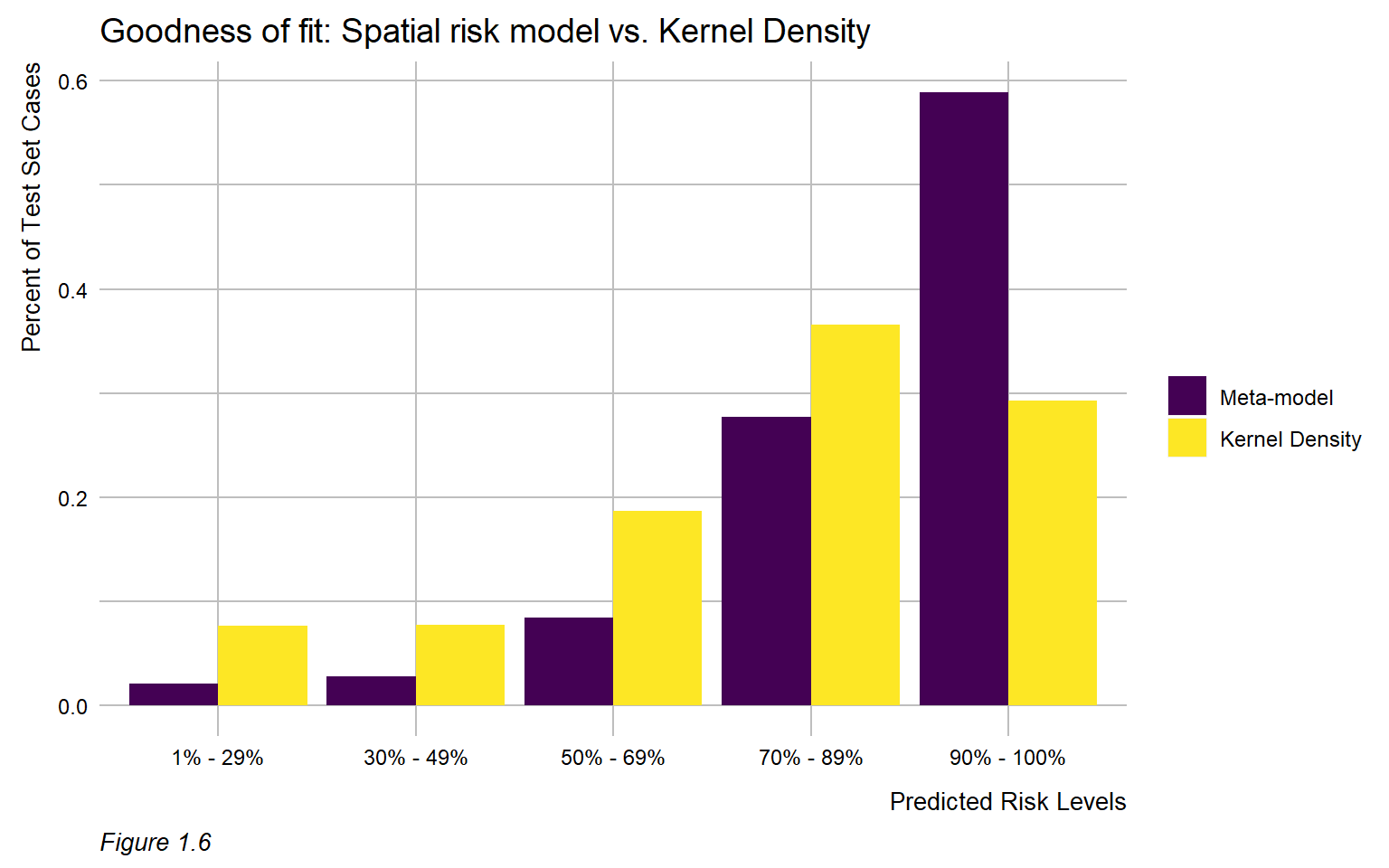
A model that is very accurate will not generalize well to other areas because exposure of maltreatment varies across space. Vice versa, a model that is too generalizable will not be accurate enough to make decisions confidently.
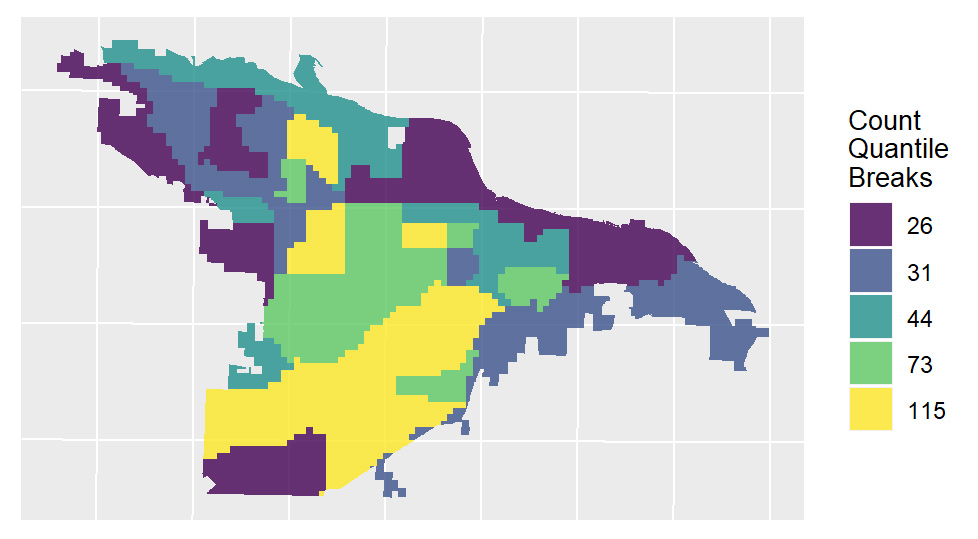
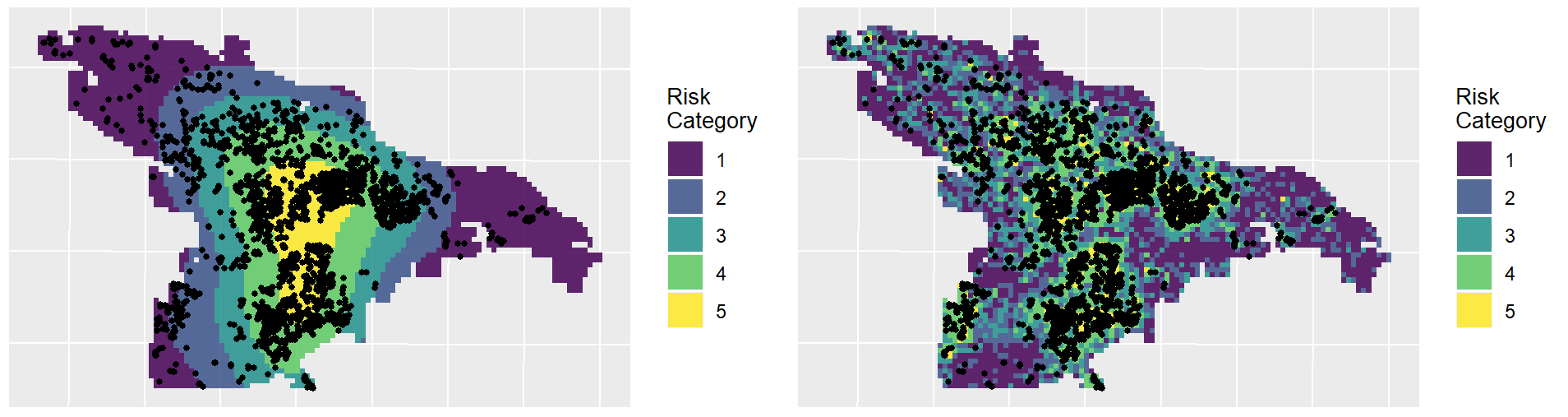
By focusing on this tradeoff, the final predictive model is able to produce highly targeted spatial risk predictions. These risk predictions are split into five risk categories, with five being the greatest risk.
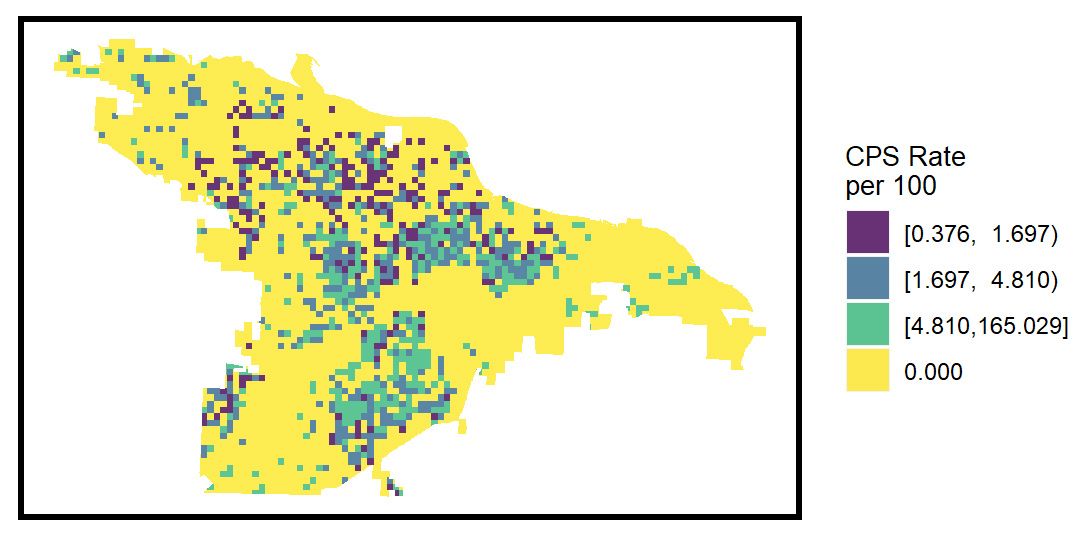
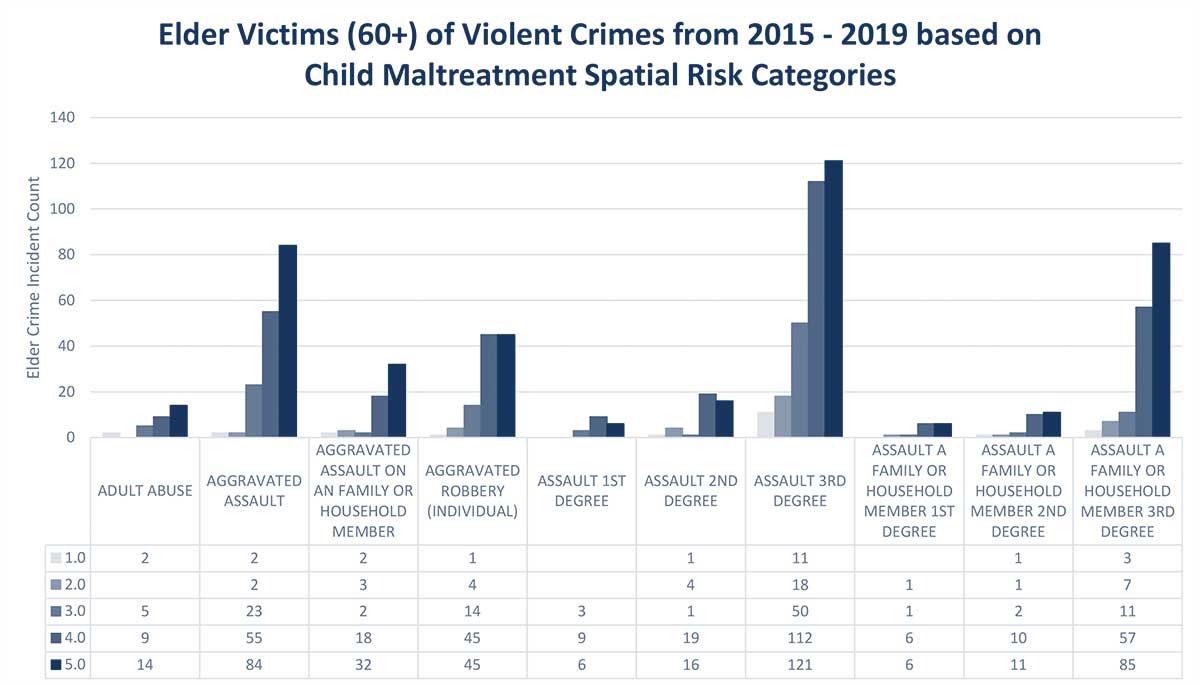
These risk predictions can then be used to evaluate whether the supply of child welfare services is properly aligned with the demand for these services. This is done by embedding the risk predictions into a strategic planning framework that helps identify resources that are optimally located relative to maltreatment risk. It is at these locations that stakeholders may wish to deploy education, outreach, and treatment programs.